We’ve noticed a lot of online discussion around GEO talks about LLMs like they’re all the same.
- “Here’s how LLMs work…”
- “To get mentioned by LLMs…”
- “We studied 10,000 prompts across multiple LLMs…”
But the reality is we’re talking about 6+ different systems that answer questions, recommend brands, and cite sources in different ways. So as marketers, we wanted to ask: Are there differences in how easy it is to influence or get mentioned in each AI tool?
The answer, as our data below shows, is yes.
We track the AI visibility of all our clients in Traqer, and we’re seeing a clear trend of three tiers of visibility between the LLMs we’re tracking:
- AIO and AI Mode – Highest visibility
- Perplexity and Gemini – Medium
- ChatGPT – Lowest visibility
Here’s a screenshot of how that data looks in our Traqer dashboard:
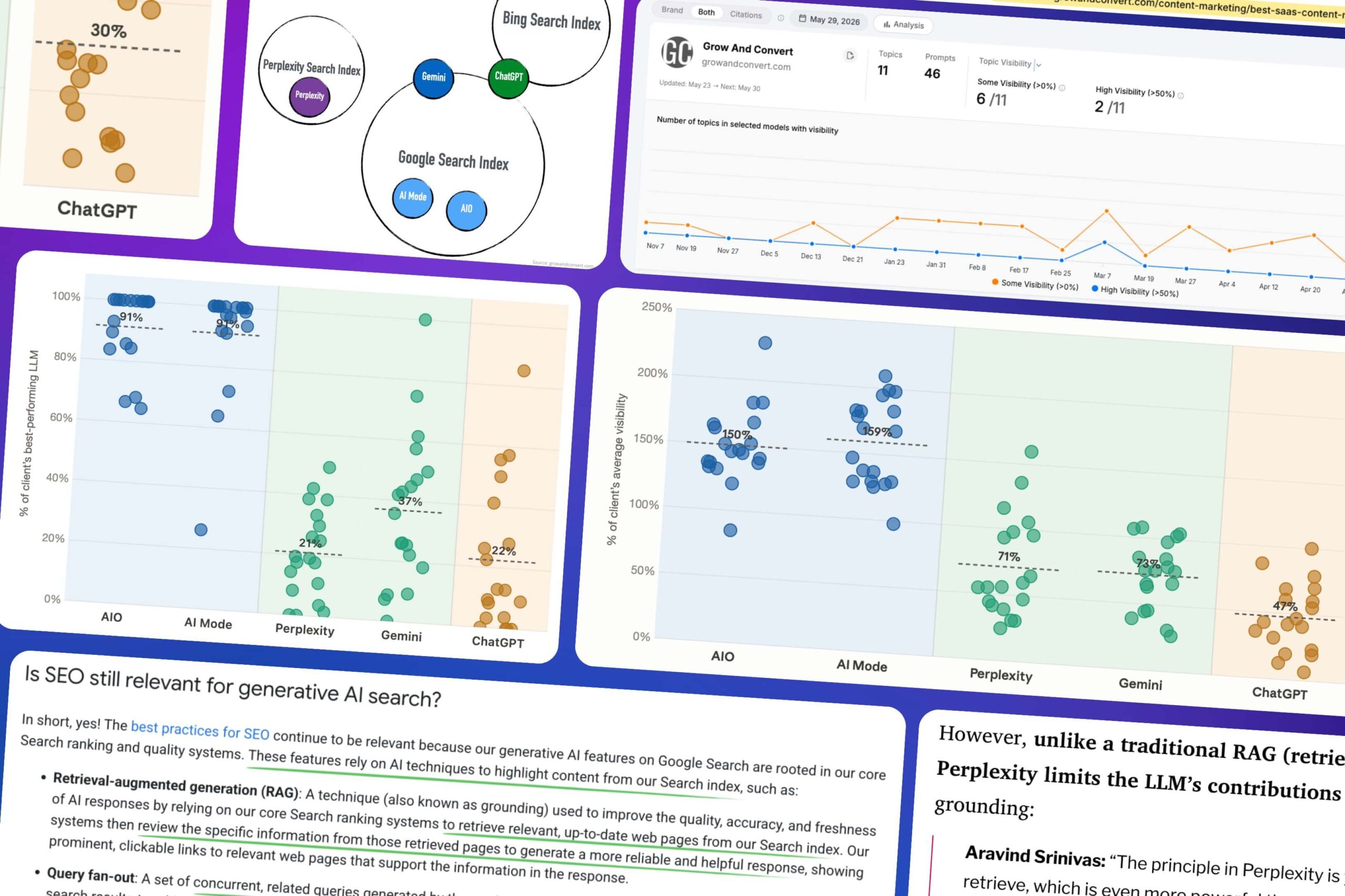
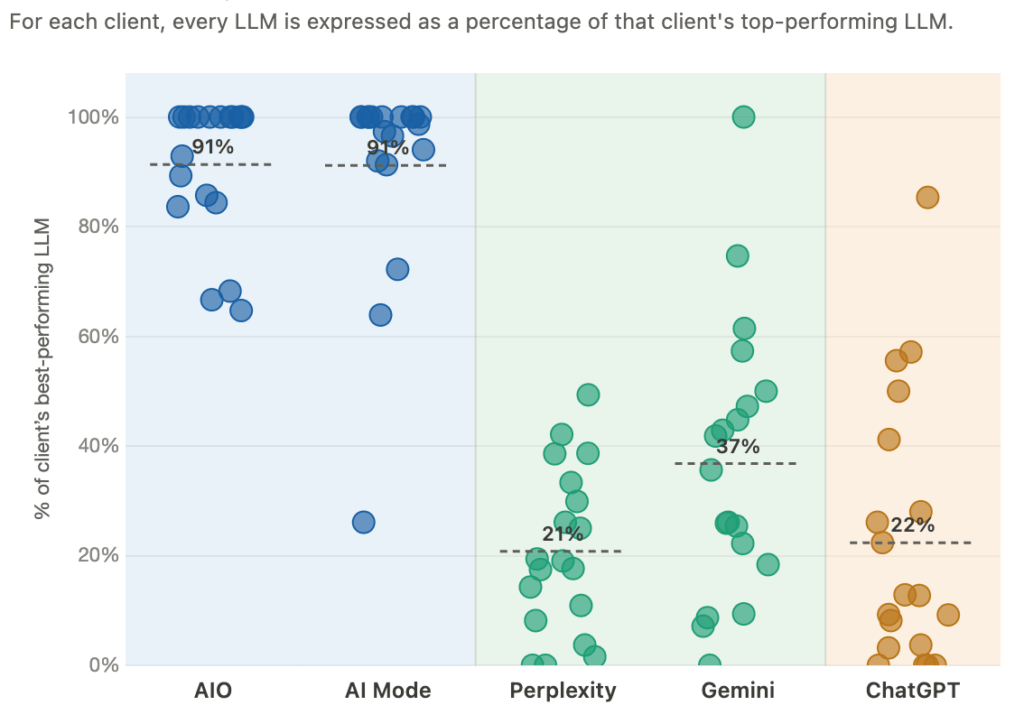
We plotted this data to see if we could find patterns in certain LLMs consistently showing higher brand visibility than others. Here is the visibility of 19 clients normalized to each client’s highest visibility LLM (which is plotted as 100%):
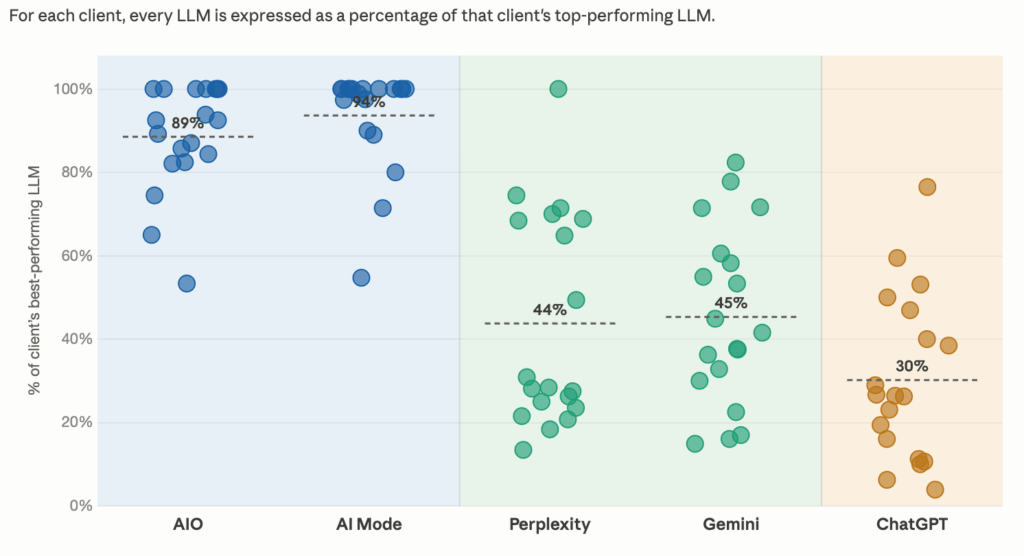
We clearly see three tiers of visibility.
Tier 1: The Google SERP LLMs (AIO and AI Mode)
These consistently show the highest visibility across our clients. In fact, either AIO or AI Mode is the highest visibility LLM (plotted as 100%) for all but one client — and that one is a brand-new client that hasn’t done any SEO and therefore has very little SEO presence.
As we’ll explain below, this is not a coincidence. AI Overview and AI Mode are not typical LLMs like ChatGPT that answer questions based on their training-data-informed understanding of the world. They behave more like summarizers of what’s ranking on Google for that topic. Our clients are doing well in AIO and AI Mode because we rank them for tons of product-focused SEO keywords.
Tier 2: Perplexity and Gemini
These, on average, show 40–50% of the visibility of the highest-performing LLM for each client. As we’ll discuss below, this suggests that Perplexity and Gemini factor in traditional search results (aka SEO) more than ChatGPT.
For Perplexity, that’s obvious because it too is a search results summarizer. But the Gemini data is interesting. It suggests that Gemini weighs live search results more than ChatGPT when generating responses.
Tier 3: ChatGPT
This data confirms what we have noticed for months: ChatGPT is the hardest LLM to influence, at least with traditional SEO. It seems to weigh search results less and rely on its training-data-informed model of the world more.
This has implications for marketing teams, both in terms of setting expectations and for guiding GEO strategy. But the biggest takeaway we want to share with the community is to stop thinking about GEO / AEO / AIO as one thing. GEO is not one battle, it’s actually multiple separate battles you are fighting simultaneously. And that may, at times, mean deploying unique strategies for each.
Data and Details
This section is for those who want to understand the details behind our data. It gets a bit technical. If you want to get to marketing implications, skip it.
The Data
What is normalized data?
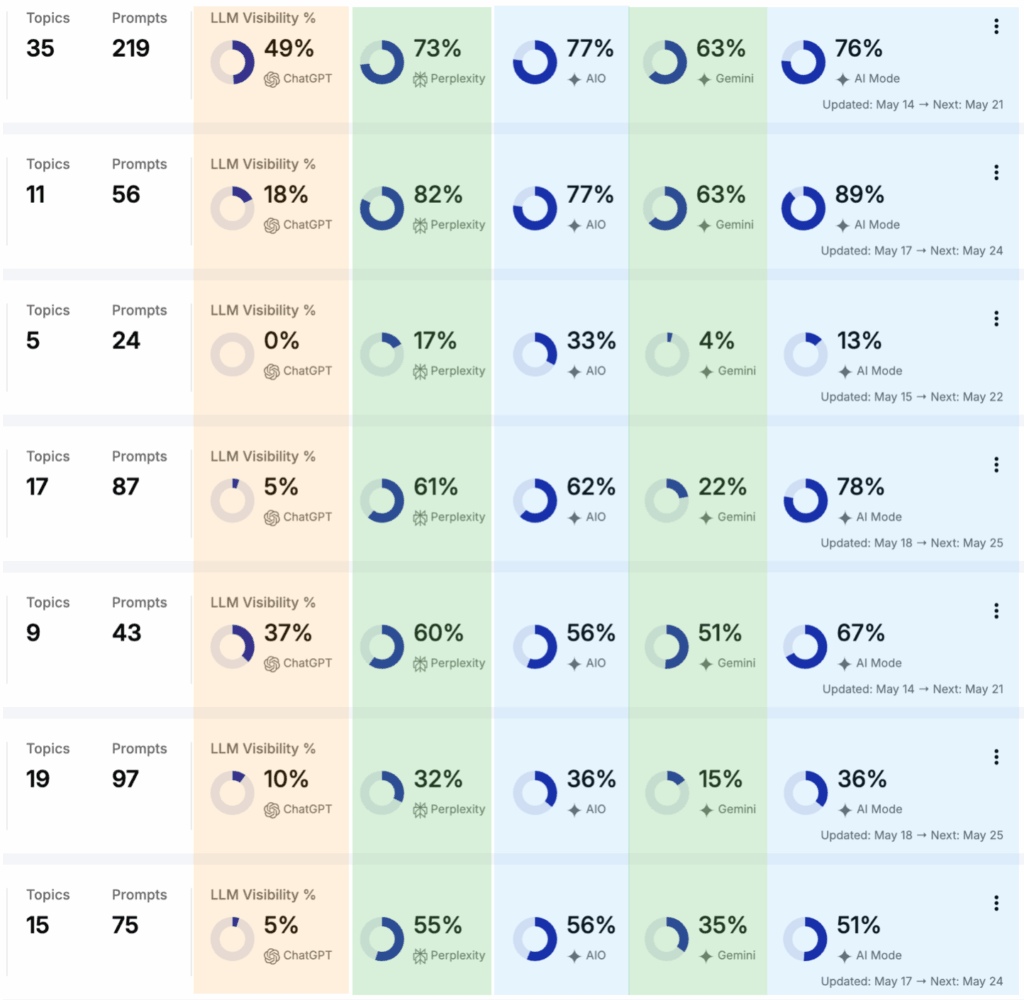
In the above graph, we say the data is “normalized” to the highest-performing LLM. What that means is we divide the visibility percentages of each LLM by the highest visibility percentage.
For example, take our own data as of this writing:

The highest visibility LLM for us right now is AIO at 67%. In the above graph, we normalized these numbers by dividing each LLM’s visibility percentage by 67%. So AIO sits at 100%, AI Mode at 97% (0.65/0.67), and so on.
Why do we normalize?
Normalizing is done whenever you want to see the relative difference between data points, which is what we’re trying to do here. We’re trying to learn, across our clients, if some LLMs are easier to get brand visibility in than others. Is it easier to be mentioned or cited in an AIO than ChatGPT, for example?
If you don’t normalize, you’ll have a brand with 80% visibility across the board and another with 8%. That doesn’t tell you much. So for each brand, we divide each LLM’s visibility number by the highest one to see, relatively speaking, which LLMs have higher visibility than the others.
Normalizing in different ways. Same result.
Note that we tested normalizing the data in different ways and we still saw the three tiers of visibility.
Above, we showed visibility normalized to each client’s highest visibility percentage. Here is the same data, normalized to each client’s AIO visibility percentage. So AIO is 100% for each client.
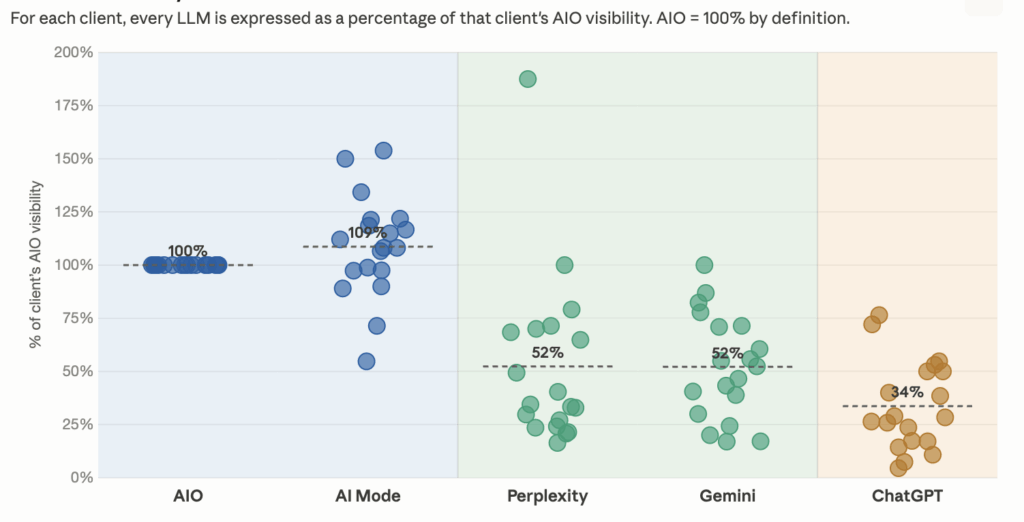
The percentages are different, but the takeaways are the same:
- AIO and AI Mode are in a tier of their own
- AI Mode has slightly higher visibility than AIO
- Perplexity and Gemini show about half the visibility of AIO and AI Mode
- ChatGPT is the toughest, at about a third of the visibility of AIO and AI Mode
Finally, here’s the same data normalized to each client’s average visibility percentage across the 5 LLMs we’re tracking:
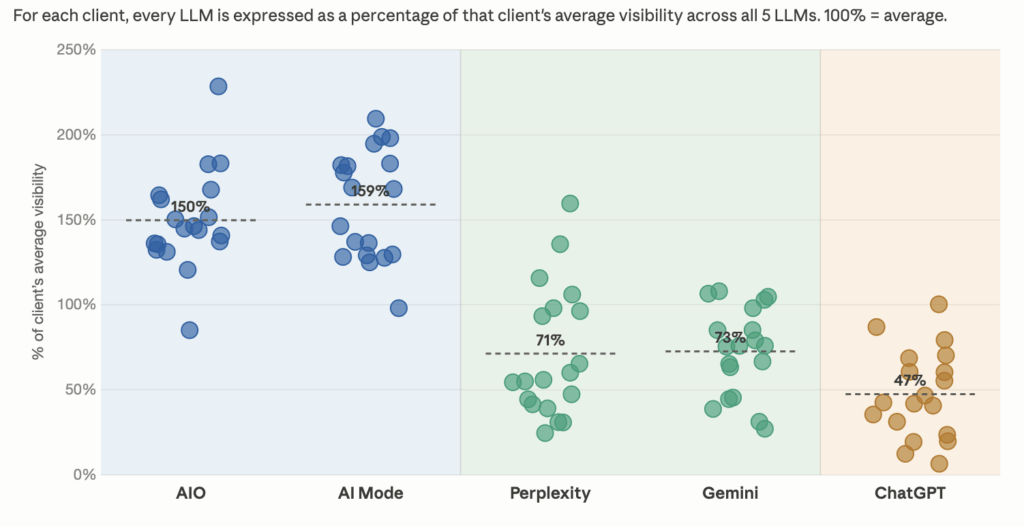
Again, different absolute values, same takeaway.
The Visibility Metric
The visibility metric we are using is the percent of tracked prompts where the brand is either mentioned by name in the output text or their website is cited as a source.
Separating Brand Mentions vs. Citations
An obvious follow-up question after seeing this data is: Does it change if we look only at mentions of the brand name in the LLM output, not citations? Reason being, having your brand mentioned by an LLM in its answer (which almost always means it’s positively recommending your brand) is far more valuable than just being one of the sources.
So we ran this same data analysis using only brand mentions and the results are almost the same, with the key difference being: Perplexity has much lower brand mentions — it’s in Tier 3 with ChatGPT from a brand mention perspective.
(I’m keeping the same color coding as the other graphs for visual clarity).
Another takeaway is that the absolute numbers are lower for ChatGPT visibility when you look at brand mentions only. Not only is ChatGPT harder to get cited relative to Google AI products, but it also looks like getting it to mention your brand in its answer seems to be even harder.
The Prompts
The prompts, themselves, are important to this discussion. As we’ve explained before, in GEO, unlike in SEO, LLMs won’t mention brands when users ask general top-of-funnel questions.
For example, if you ask ChatGPT, “Help me build a content strategy for AI search”, it’ll answer your question but won’t say something like “Grow & Convert is an agency that can help you” (unless the follow-up conversation naturally moves in that direction). Those top-of-funnel informational prompts shouldn’t be a priority in your GEO strategy.
Instead, we recommend marketing teams focus on “bottom of the funnel” or product-centric topics for GEO because that’s where you actually have a shot at being recommended or mentioned.
As a result, the prompts we’re tracking for clients, and therefore are part of this study, are bottom-of-funnel and product-centric.
Here are examples:


Note that our tool Traqer guides you towards these bottom-of-funnel prompts and topics naturally. You can try it and get your own visibility numbers for free at Traqer.ai.
Explaining the Differences: Search-Based vs. Training-Data-Based LLMs
The core reason visibility differs in this way is how the LLMs work. Namely, I want to introduce a concept that will help us understand these:
- Search-based LLMs
- Training-data-based LLMs.
AIO and AI Mode are “search-based LLMs” because they literally are built to summarize search results. Perplexity actually is, too; it just uses a different search index, as we’ll explain below.
In contrast, ChatGPT, Gemini, and others, while they can and do search the web, are general-purpose LLMs that don’t necessarily need to search the web to answer users’ questions. They have an internal model of how the world works that they can use to answer questions.
I find it convenient to think of it visually in this way:
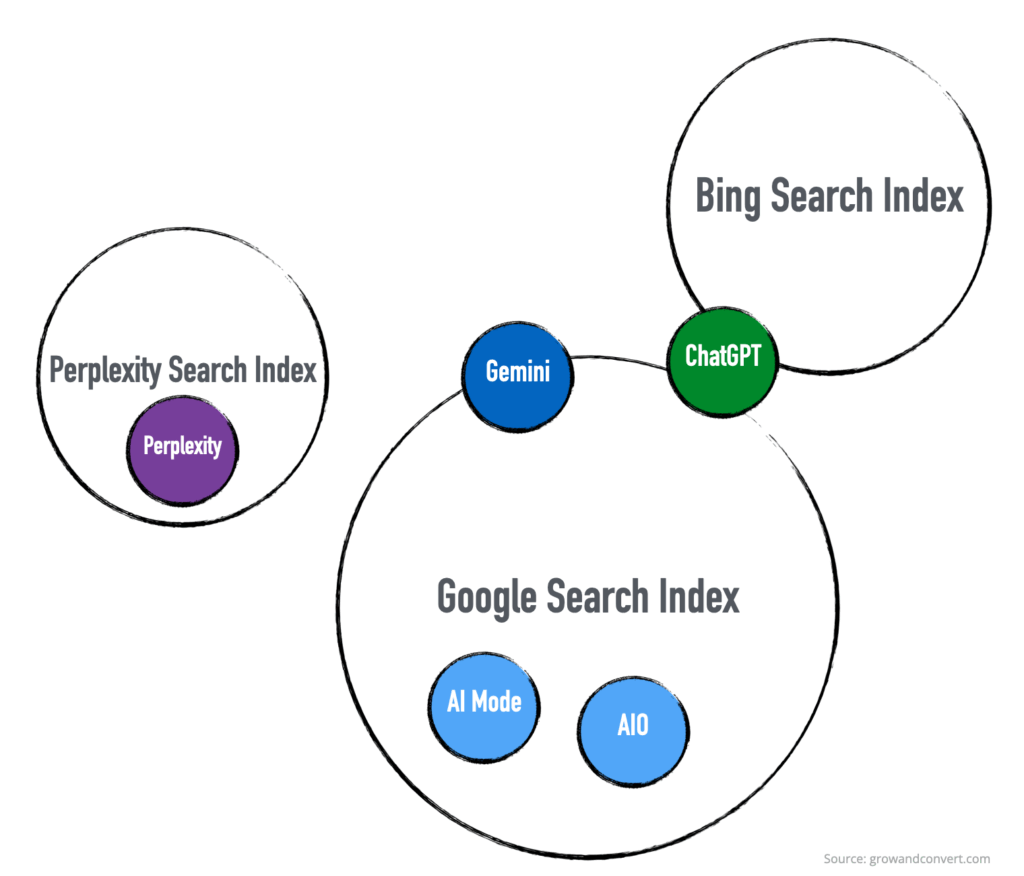
Caveat: This is intentionally oversimplified to help people quickly grasp the basics. I’m sure there are details and data sources not shown above. For example, Perplexity says they now use their own index, but in reality they may still use Google and Bing to supplement their index (they list both as “subprocessors” on their site); people debate how much ChatGPT uses Google versus Bing; and so on. So don’t take this diagram as the ultimate truth, but rather a convenient and quick mental model.
So the fundamental reason for the differences in visibility is that we rank our clients for relevant SEO terms on Google.
LLMs that rely more heavily on Google search results (e.g., AIO and AI Mode) mention or cite our clients more often.
LLMs that rely less on Google search (e.g., ChatGPT) are harder to influence through SEO rankings.
AI Overview and AI Mode are “RAG”s Built to Summarize Search Results
On this page of Google’s own documentation, they explain how AI Overview and AI Mode are based on search results. Here’s a critical line from that page saying they use AI to highlight content from their search index:
“The best practices for SEO continue to be relevant because our generative AI features on Google Search are rooted in our core Search ranking and quality systems. These features rely on AI techniques to highlight content from our Search index.” (emphasis mine)
That page goes on to say these AI features on the SERP work as a retrieval-augmented generation system (RAG), meaning they are “relying on our core Search ranking systems to retrieve relevant, up-to-date web pages from our Search index”.

Finally, look at the note on “Query fan-out”. This helps explain why AI Overview or AI Mode doesn’t exactly mimic the organic results below. It’s because when a user enters a search query, Google runs additional related queries and synthesizes all of the results into one answer.
In short, when a user searches in Google, AI Overview and AI Mode read through the traditional organic search results (for your query and related queries) and use them to generate their responses. So it’s no wonder we’re seeing very high AI visibility numbers for our clients, who we’ve already ranked on Google for all kinds of bottom-of-funnel, high-buying-intent SEO keywords.
You can see multiple examples and screenshots of one of our clients being cited and mentioned in AI Overview or AI Mode in this case study.
Perplexity Is Also Search-Based, but Its Index Is Different Than Google’s
Perplexity’s CEO has said the same thing about how it works, and actually gone further to say Perplexity is explicitly built to not say anything that isn’t supported by the search results.
This is articulated nicely by Ethan Lazuk, who quotes the Perplexity CEO on Lex Fridman’s podcast:

Perplexity is literally using this feature as a differentiator: not only do we rely on search results, we are also preventing our tool from hallucinating by forcing it to not say anything that the search results don’t say.
Then why are we seeing lower visibility in Perplexity than in AIO and AI Mode? If it’s also fully reliant on search results, shouldn’t we also see Tier 1-level visibility numbers for Perplexity?
Frankly, we were surprised by this. While we don’t know for certain, the most reasonable explanation is that Perplexity’s search index is different from Google’s, so its results are not going to be the same.
Specifically, Perplexity’s own engineering blog confirms they used to use 3rd party search APIs (aka Google, Bing, etc.) but that got expensive and didn’t scale, so they built their own crawler and index. They also actively decide which documents to keep “hot,” meaning their retrieval works fundamentally differently than Google’s.
Multiple sources have also noted that Perplexity’s index is smaller than Google’s.
In other words, yes, Perplexity is also a search-based LLM, but it’s not Google, and therefore its results don’t perfectly overlap with Google’s.
The GEO implication, from our data, is that if you rank well on Google (as our clients do), you can expect around half the visibility for bottom-of-funnel prompts in Perplexity as you see in AIO and AI Mode.
Training-Data-Based LLMs: Gemini and ChatGPT
In contrast, ChatGPT and Gemini don’t need to rely on search results to answer a user’s question. They already have an existing understanding of the world, including your product space, built into them. AI researchers call this “parametric memory”: the models were given famously large amounts of data when they were first trained, and they converted that data into mathematical weights and patterns about how concepts in the world work. Those weights are called “parameters,” hence the term.
They Can Recommend Products from Training Data Alone
This parametric memory includes an understanding of your product space. That’s why even if you turn search off or ask ChatGPT to recommend products without searching the web, it can. Here’s an example.

ChatGPT doesn’t need to search the web to recommend HubSpot, Salesforce, and Pipedrive. Those are household names in CRMs, so they must have been all over its training data, and it recommends them easily.
This existing understanding of the world is what you are fighting against when you’re trying to do “GEO” on these training-data-based LLMs.
Search-Based LLMs Can’t Recommend Products Without Searching
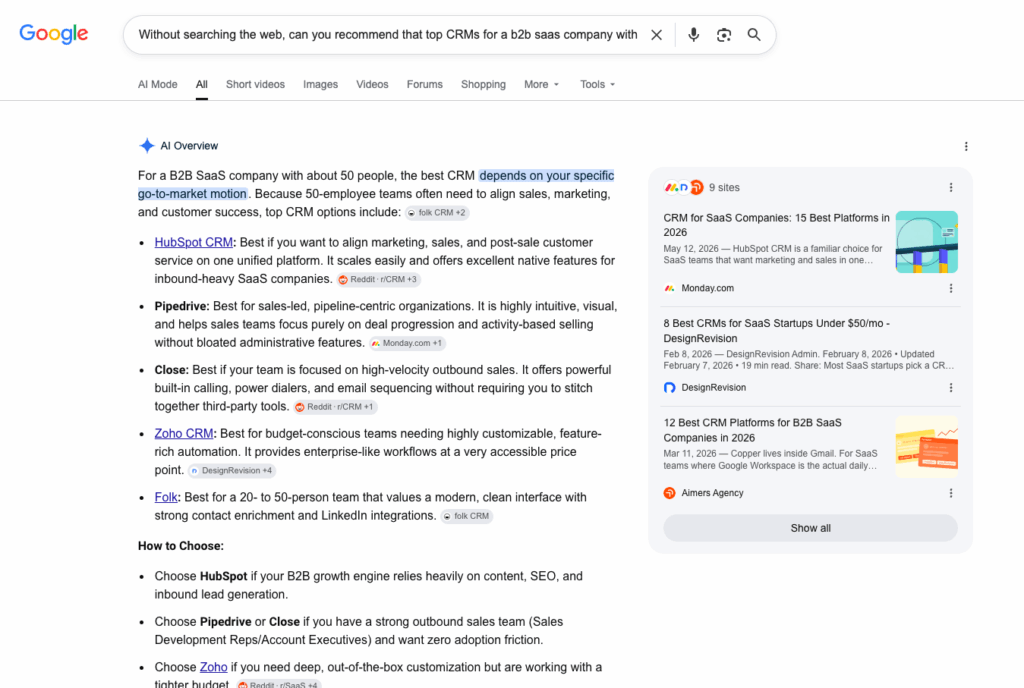
Note that if you ask any of the search-based LLMs to not search the web, they can’t do it. They are built to search the web. That’s how they get their information.
Here’s Google AIO’s response to the same prompt. It searches the web every time, even though I asked it not to. Every bullet and paragraph has a citation:
And here’s Perplexity’s answer. It literally says “Searching the web” as it thinks…
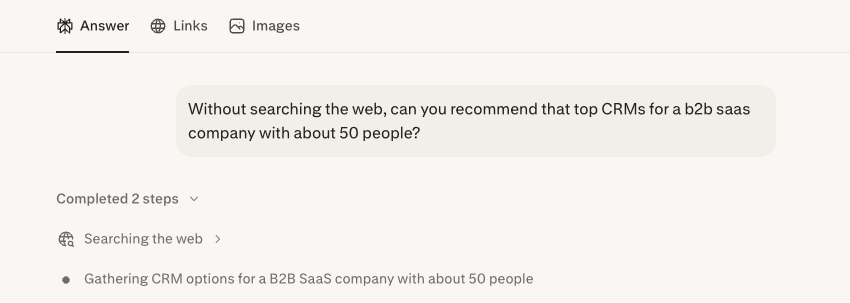
How Much Does ChatGPT Weigh Its Parametric Memory vs. Search Results?
Of course, no real user will type “Without searching the web” at the beginning of their prompts. They’ll just ask for product recommendations; for product and brand queries specifically, in our experience, basically every LLM, including ChatGPT, almost always searches the web.
Here’s me asking ChatGPT the same question but removing “Without searching the web” in my prompt. Note how even though it recommends HubSpot and Salesforce as the top two options again, this time it cites a source for each:
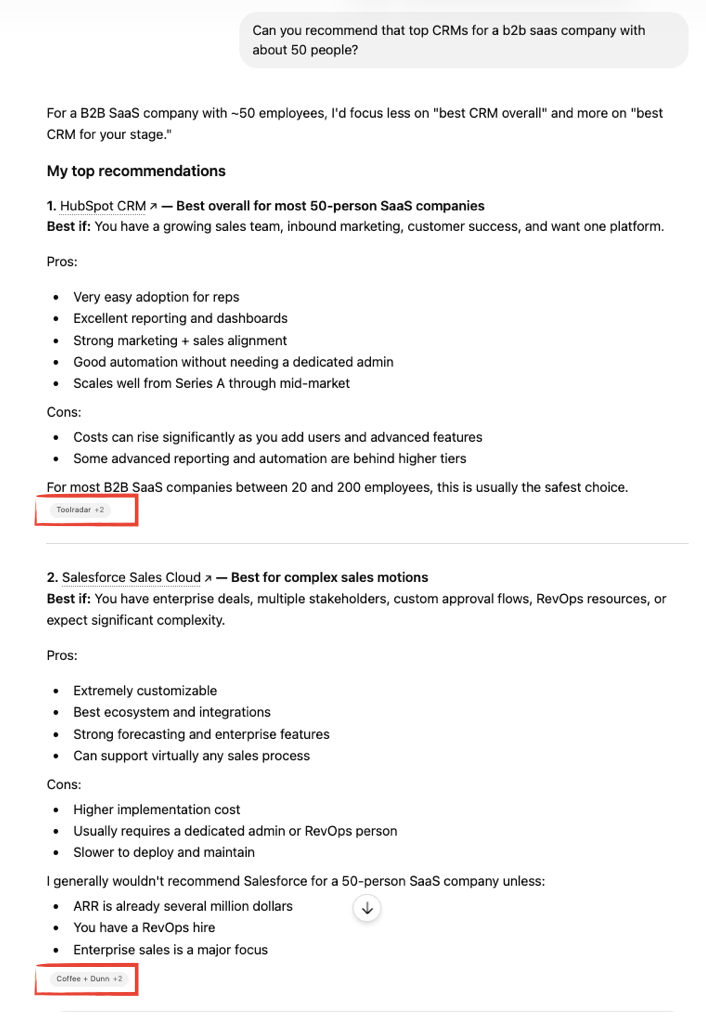
This takes us to the central question of how to influence training-data-based LLMs’ responses: How much are they actually factoring in what the search results say?
The short answer is people don’t really know. Above, it’s notable that ChatGPT recommended HubSpot and Salesforce both times I asked: with and without searching the web. So is it using the search results to inform its decision or to justify the decision that it already made from its parametric model? It’s not clear.
Query Burst’s article on this topic talks about “the Nike effect”, which is basically exactly what I’m showing above with CRMs: if you asked ChatGPT about running shoes and hypothetically none of the search results it pulled up mentioned Nike, ChatGPT would probably still recommend Nike because Nike is all over its training data.
SparkToro’s study on how much variance there is in the brands that LLMs recommend also hints at a similar conclusion. They ran the same prompts asking for products multiple times and saw huge variability in the brands LLMs recommended. But they note that despite this variety, the top 3 most popular products in each category are included in the answer 64–73% of the time. That very likely means if you are baked into the parametric model as one of the most popular brands in your space, you’re likely to get recommended regardless of what the search results say.
And, like I said above, the challenge for smaller brands is if you aren’t one of the top brands in your space, it’s harder to get mentioned by these training-data-based LLMs. That’s why we see lower visibility numbers for ChatGPT compared to the search-based ones.
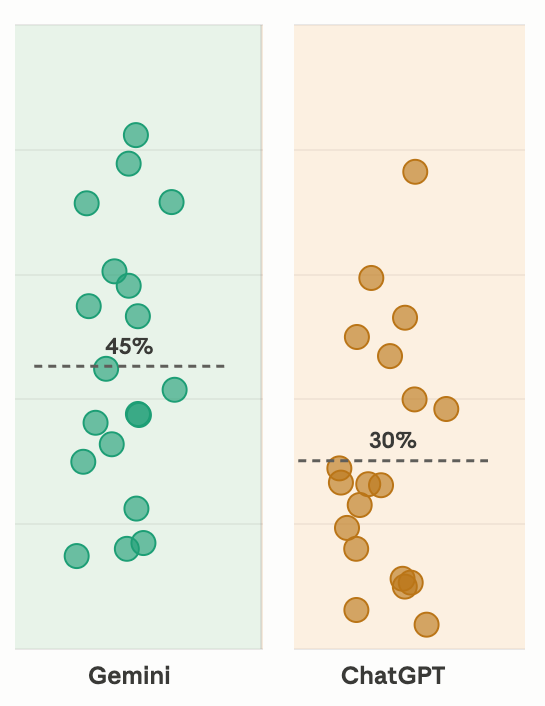
Gemini Seems to Weigh Search More Than ChatGPT
Notably, even though I’m including Gemini in the “training-data-based LLMs” category, it also searched the web and cited sources even when I asked it not to.

And that takes us to why our clients, on average, have higher visibility in Gemini versus ChatGPT.
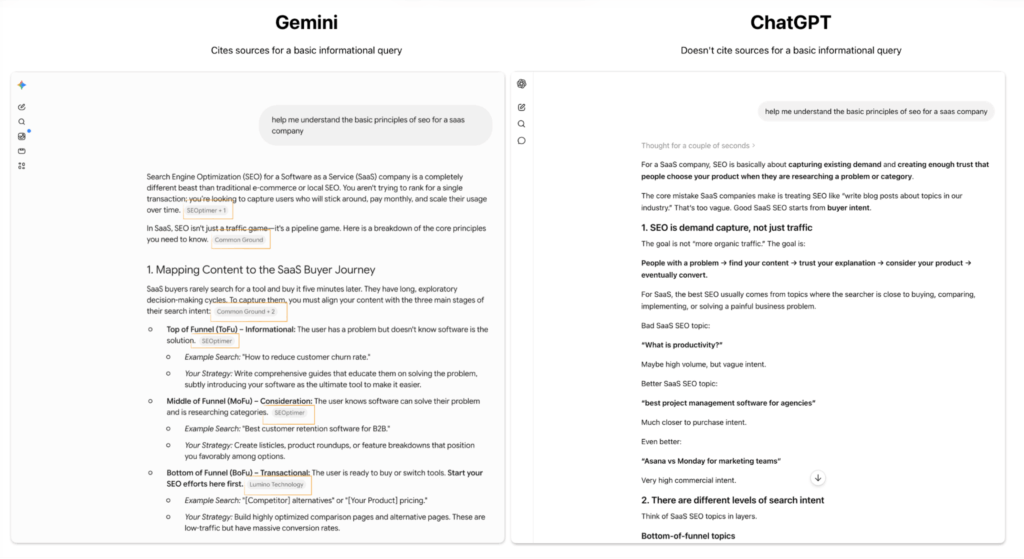
On paper, Gemini is a general-purpose LLM like ChatGPT, not a search summarizer like AI Overview, AI Mode, or Perplexity. It has a “parametric model” of how the world works. You can ask it to make you an image or do spreadsheet math — tasks that AIO, AI mode, or Perplexity can’t do.
But our data points to something else: Gemini seems to rely more on search results to produce its answer than ChatGPT (and perhaps other general-purpose LLMs).
It also seems to search the web way more often, as the example above shows on CRMs. To test this, I also asked it to just explain the basic principles of SEO to me, thinking that this should not require a web search. But it still searched the web and cited sources when ChatGPT didn’t.
I did manage to get Gemini to not search the web when I asked it to give me a basic overview of Newtonian physics, so it can answer some questions without a search. But what we’re seeing in these anecdotes and our data is that it seems to search the web more than ChatGPT.
Other people have noted this as a benefit of Gemini whenever you need up-to-date, accurate information. It’s better at searching; it relies on search more, so it hallucinates less.
But our data above pokes at this in a way that’s more interesting for marketers: being visible in traditional search (SEO) seems to give you higher visibility in Gemini than in ChatGPT, since Gemini both searches more and seems to integrate those search results into its answers more. You can set expectations with yourself, your leadership, or your clients accordingly.
Strategies to Get Recommended by Training-Data-Based LLMs
1. Branded Content Is Influencing ChatGPT Visibility
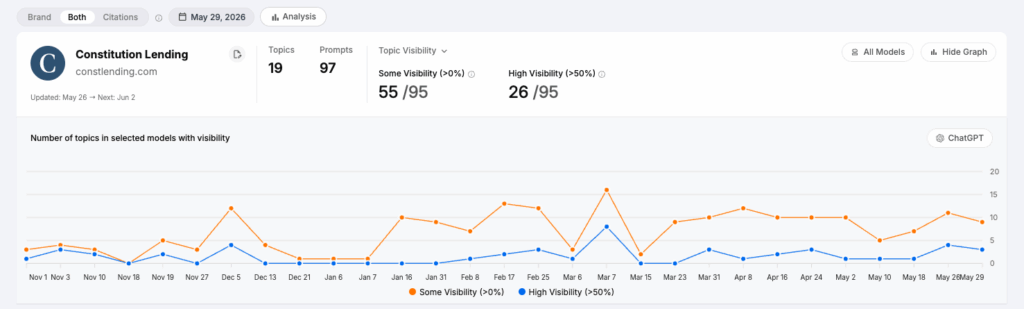
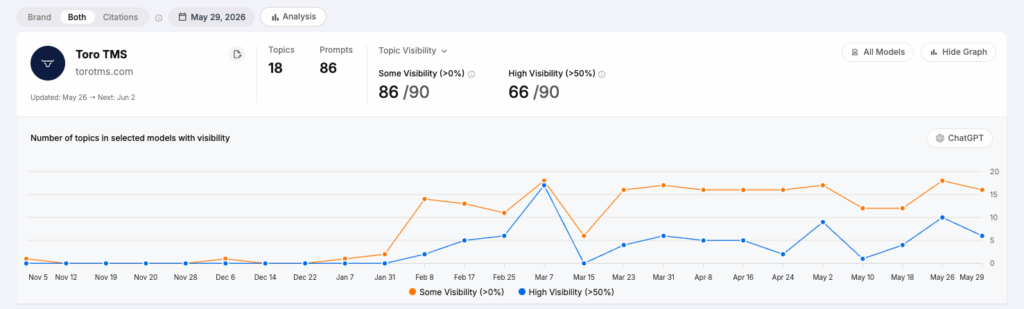
First, despite ChatGPT having lower visibility scores than the other LLMs, we do see growing visibility there for our clients, including for brands that are not the well-known incumbents.
Here’s ChatGPT visibility for relevant topics for our real estate lending client, Constitution Lending, who is not an incumbent in their space:
Or Toro TMS, also a new-ish player in their space:
Or even for us:
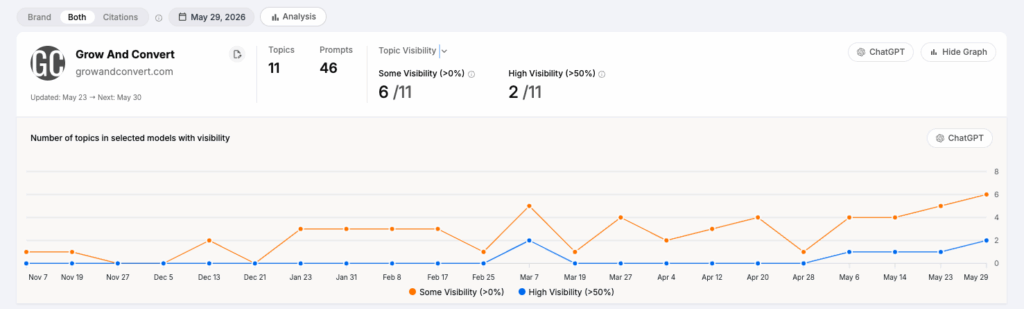
These aren’t hockey sticks, which, as per everything we stated above, is not going to happen because ChatGPT seems to be harder to influence. But it’s growth nonetheless.
2. Citation Outreach
As per our prioritized GEO pyramid, owned content isn’t the only lever you can pull to influence LLMs. You also have Tier 2: Off-site Mentions.

Off-site mentions means reaching out to other sites (besides your own) that are being cited by LLMs in the topics you’re interested in and asking them to include or mention your brand.
How do you figure out what sites those are? You can do it manually (by just asking ChatGPT a prompt that you want to show up for and see who it cites), but it’s more efficient to use AI visibility software that will list all the cited sources for the prompts you are tracking.
For example, here are the citations used for the topic “content marketing agency” using our tool, Traqer.
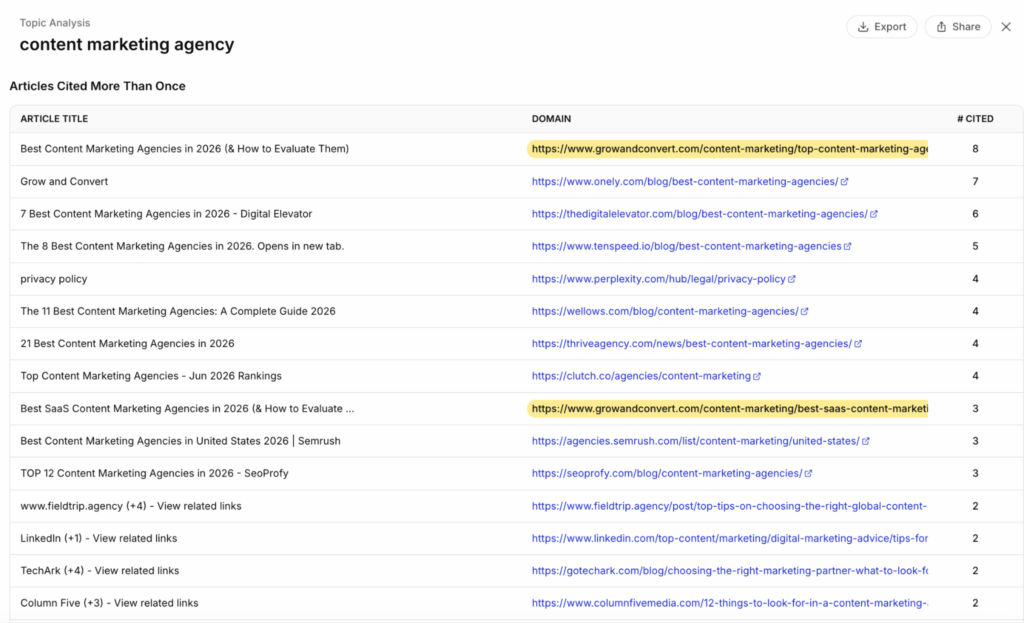
One important caveat when doing this: don’t just assume Reddit is the main place where you need to get mentioned; actually look at the sites being cited for your prompts of interest. In the example above, no Reddit threads appear as the top sources.
As we show in detail in this study, for most product queries, industry publications are cited way more than general sites like Reddit or Wikipedia.
3. Topic-Based Visibility (Not Single Prompts) Is What Matters In The Real World
There is an extremely important difference between GEO and SEO that most people overlook: in GEO (AI search), we don’t really know what users are typing into LLMs. And even if we did, we can’t reproduce the output a real user gets because their output will be heavily personalized to their conversation history and context (our full explanation of this phenomenon is here: Invisible Prompts).
This context and personalization in generating answers mean LLMs recommend products and services to users based on extremely specific details about their situation and pain points.
While that makes measuring your true AI visibility hard (your visibility tool won’t be able to see the responses that real users get because that’s personalized to them), it also gives you an avenue to gain visibility: Publish content that shows how your product or service solves very specific problems for very specific users.
We discuss this at length in Topic-Based GEO.
Final Thoughts
The takeaway from this data is less about the absolute visibility numbers (brands have large differences in visibility in AI search, as the plots above show), and more about these overall truths:
- AI visibility isn’t one thing: each LLM should be treated differently
- It’s very likely that the main differences in visibility between the brands are from how much they rely on Google’s search results
- To improve visibility, have content on your own site that’s visible when LLMs search the web and/or get your brand mentioned in other pages that are ranking for those relevant search terms
Join the Grow and Convert Newsletter
Get our marketing ideas emailed weekly.
Explore Articles By Categories












Explore our Videos






